Filtrado y uso de query con Pandas en Python
Veremos ejemplos de uso de query con Pandas en Python, así como las diferentes formas de hacer filtrado en un dataset empleando Pandas. Utilizaremos las siguientes operaciones de Pandas: unique, isin, contains, sort_values, groupby, apply, y to_csv.
Éste artículo cuenta con una explicación en video. Lo puedes ver aquí: https://youtu.be/0DpbPTG4358
Un aspecto importante en el análisis de datos es realizar correctamente el filtrado de un dataset. Veamos las diferentes formas de hacer el filtrado en Pandas.
En los siguientes ejemplos hacemos uso del siguiente conjunto de datos:
https://drive.google.com/file/d/1i5s30GCPTqg07N4JU7T2l0Uu6lY7LU_z/view?usp=sharing
Filtrar por columna
Podemos seleccionar toda una columna. Para esto únicamente debemos incluir entre corchetes el nombre de la columna a seleccionar.
print (df["county"])
Pero si deseamos unas cuantas filas únicamente, podemos especificar el rango:
print (df["county"][5:10]) # imprime de la linea 5 a la 10 print (df["county"][:10]) # imprime las primeras 10 print (df["county"][-5:]) # imprime las últimas 5.
Nota: podemos escribir directamente el nombre de la columna sin los corchetes. La primera de las líneas de código anteriores, quedaría así:
print (df.county[5:10])
Para los siguientes ejemplos haremos uso de un dataframe llamado df3, que contiene las columnas “condado”, “candidato”, “partido” y “votos”.
df3 = df[["county", "candidate", "party", "votes"]]
Filtrar con condiciones
Para filtrar con condiciones, debemos escribir la condición dentro de corchetes. Por ejemplo, si deseamos mostrar a los que tienen más de 200 mil votos en un condado, podemos escribir:
print (df3[df3.votes>200000])
Lo anterior nos crea una matriz de valores booleanos True o False, de acuerdo a la condición expresada (df3.votes>200000). Ésta matriz es pasada al dataframe df3.
Filtrar con dos condiciones
Si tenemos dos condiciones a cumplir, cada condición la ponemos dentro de paréntesis y las unimos usando un operador lógico (&, |). En el siguiente ejemplo deseamos mostrar los votos obtenidos por el partido demócrata en el condado de Manhattan.
print (df3[(df3.county=='Manhattan') & (df.party=='Democrat')])
Uso de Query con Pandas en Python
Vamos a realizar la misma consulta (mostrar los votos obtenidos por el partido demócrata en el condado de Manhattan) pero usando el método query.
print (df3.query("county=='Manhattan' and party=='Democrat'"))
La diferencia radica en que solo se especifica el nombre de la columna y todo va entre comillas como si se tratara de una cadena.
Manejo de variables y uso de query con Pandas
Podemos incluir una variable dentro del query. En el ejemplo anterior deseamos que Manhattan esté dentro de una variable llamada “condado”. Entonces el query quedaría así:
condado = 'Manhattan'
print (df3.query("county==@condado and party=='Democrat'"))
isin y uso de query con pandas
Isin nos permite comprobar si un valor está dentro de una lista. Por ejemplo, si la consulta fuese: “Mostrar los votos de los condados de Autauga y Baldwin”, si lo quisiéramos hacer con dos condiciones quedaría así:
#1 Usando matriz de valores booleanos
print (df3[(df3.county=='Autauga') | (df3.county=='Baldwin')])
#2 Usando query
print (df3.query("county=='Autauga' or county=='Baldwin'"))
Observamos que se realizan dos consultas, una por cada valor buscado. Pero como es la misma columna, podemos utilizar el método isin:
print (df3[(df3.county.isin(["Autauga","Baldwin"]))])
Y obtendremos los mismos resultados.
Contains
Si la consulta requiere que comprobemos solo parte del valor del dato, podemos utilizar contains en el caso de las cadenas de caracteres. Por ejemplo, si deseamos mostrar los votos de los condados que contengan la palabra ‘Saint’, podemos hacer lo siguiente:
print (df3[df3.county.str.contains('Saint')])
Lo que nos devolverá valores correspondientes a Saint Francisc, Saint Agatha, y Saint Laurence.
Ordenamiento en Pandas
¿Quiénes fueron los 3 candidatos que más votos obtuvieron en un condado? Para contestar ésta pregunta debemos realizar una operación de ordenamiento. De esa forma podemos extraer los 3 primeros resultados que nos arroje Pandas.
Código:
dfordenado = df3.sort_values(by="votes", ascending=False)
print ("Ordenados por votos de mayor a menor")
print (dfordenado.head(3))
Le estamos diciendo que al dataframe de nombre df3, lo ordene (sort_values) con base en la columna “votes“, en forma descendente (ascending=False). Como solo deseamos 3, utilizamos head(3) para obtener solo los tres primeros.
Agrupamiento en Pandas
El agrupamiento nos permitirá realizar operaciones (como contar o sumar) sobre un subgrupo dentro de un dataframe. Por ejemplo, si deseamos el total de votos por estado y por partido, tendríamos que agrupar todos los votos de un estado, y después agrupar todos los votos de cada partido. Hacerlo con Pandas es muy sencillo:
#print ("total de votos por estado y por partido")
#print (df.groupby(["state", "party"]).sum())
Ésta operación nos agrupa todos los registros, primero por estado y luego por partido y realiza la suma de las columnas numéricas, si solo queremos la de votos deberíamos especificarla: df.groupby([“state”, “party”])[“votes”].sum()
Aplicar una función a una columna en Pandas
Código:
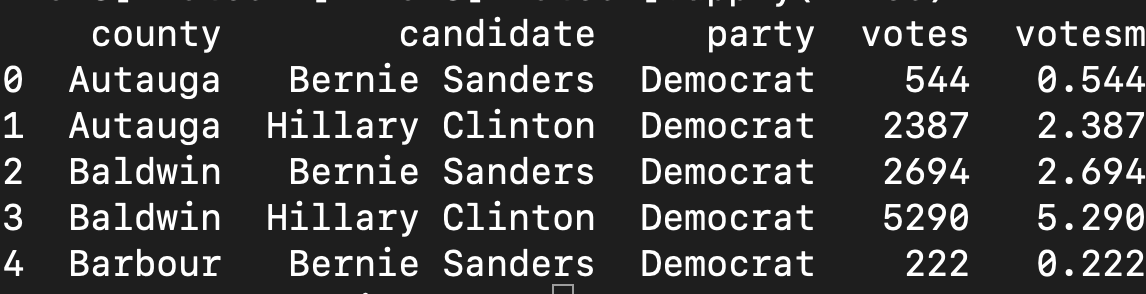
def miles(x): return x/1000 df3["votesm"] = df3["votes"].apply(miles) print (df3.head())
Primero estamos creando una función llamada miles que recibe un valor (x), y lo regresa dividido entre 1000. (return x/1000).
Luego creamos una columna llamada “votesm” y le asignamos el resultado de aplicar a cada valor de “votes” la función miles.
El resultado se verá así:
Guardar un dataset como csv
Para guardar un dataset como csv, debemos especificar el nombre del archivo donde se guardarán los datos y hacer uso del método to_csv.
df3.to_csv("filename_df3.csv", index=False)
Éste artículo está explicado en vídeo. Te lo dejo a continuación: