Introducción al machine learning en Python
En este artículo veremos una introducción al machine learning en Python, cuáles son las librerías que se necesitan, los principales algoritmos, así como la diferencia entre el machine learning y la programación tradicional.
El machine learning o aprendizaje automático, es una técnica o una rama de la inteligencia artificial, que permite que los sistemas aprendan. Esto se consigue porque pueden analizar los datos para buscar patrones, y así realizar predicciones.
Como ejemplo de aplicación, las instituciones bancarias lo utilizan actualmente para prevenir fraudes en tarjetas de crédito, logrando incluso suspender una compra cuando detecta que proviene de un usuario no autorizado. (Vea también: Introducción a la inteligencia artificial)
Machine Learning vs Programación Tradicional
En la programación tradicional se escriben todas las reglas que el programa necesita para proporcionar un resultado. Luego, al programa se le proporcionan datos de entrada que serán procesados con base en las reglas y de esa forma se obtienen los resultados esperados.
Por el contrario, en Machine Learning el sistema es entrenado en vez de ser programado explícitamente. Para esto, se necesitan los datos de entrada y los resultados esperados. Al final obtenemos un conjunto de reglas, también llamado modelo.
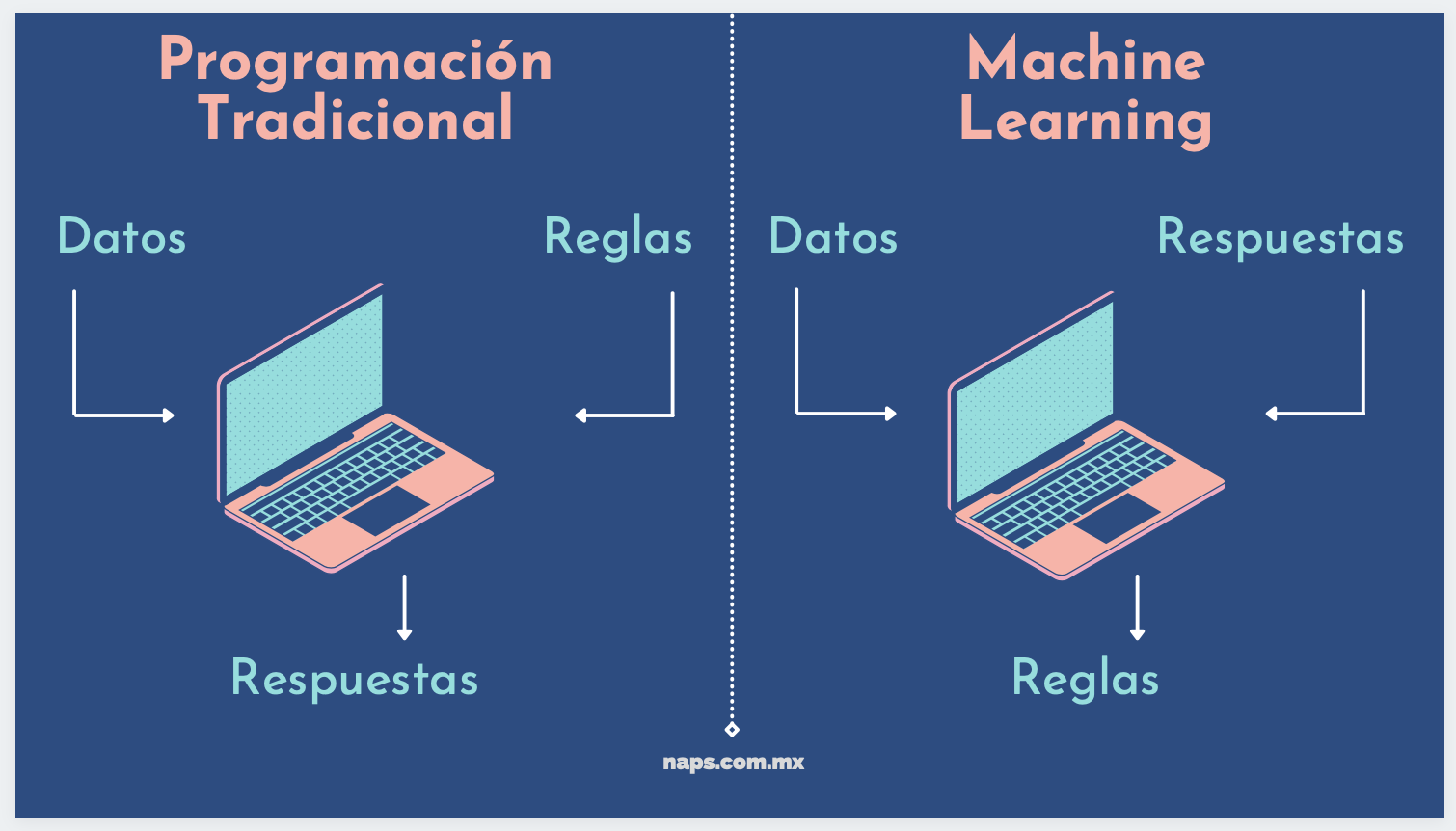
Machine Learning vs Programación Tradicional
Machine Learning en Python: Bibliotecas esenciales
Para hacer Machine Learning en Python usaremos las siguientes bibliotecas:
Pandas. Para obtener y manipular los conjuntos de datos
NumPy. Para trabajar los datos en forma de matrices y así mejorar el rendimiento del modelo.
Matplotlib / Seaborn. Para crear gráficos que nos permitirán observar las relaciones entre los datos
Scikit Learn. Es la biblioteca principal de Machine Learning en Python. Contiene diferentes algoritmos que pueden ser utilizados para entrenar nuestros modelos.
Pickle. Nos permite almacenar los modelos en archivos y de esa forma poderlos utilizar posteriormente.
Scipy. Contiene módulos para tareas de ciencia e ingeniería.

Machine Learning en Python Bibliotecas necesarias
Machine Learning en Python: Principales algoritmos
Scikit Learn nos ofrece una amplia variedad de algoritmos para producir nuestros modelos. Entre ellos están los siguientes.
Para aprendizaje supervisado
En aprendizaje supervisado disponemos de los datos etiquetados, es decir, los datos incluyen correctamente el atributo objetivo.
Cuando el atributo objetivo es un valor continuo:
- Regresión Lineal
- Árboles de decisión
- Random Forest
Cuando el atributo es una categoría:
- KNN
- Regresión logística
- Naive-Bayes
- SVM
- Árboles de decisión
Para aprendizaje no supervisado
En aprendizaje no supervisado no disponemos de los datos ya etiquetados. Por así decirlo, no le decimos la respuesta correcta en el momento del entrenamiento, sino que el algoritmo aprende de los mismos datos.
Cuando el atributo objetivo es un valor continuo:
- SVD
- PCA
Cuando el atributo es una categoría:
- K-Means
- DBScan

Machine Learning en Python Principales algoritmos
Conclusión
Python es un lenguaje de programación que nos permite crear modelos de Machine Learning a través de la librería sklearn, misma que contiene una amplia variedad de algoritmos para utilizar.
Referencias
Ohlsson (2020). The nature of machine learning projects. Disponible en [https://labs.sogeti.com/the-nature-of-machine-learning-projects/]