Ejemplos en Matplotlib de 5 tipos de gráficos
Veremos ejemplos en Matplotlib de 5 tipos de gráficos. Para realizar gráficos de datos en Python se utiliza la librería Matplotlib. A continuación veremos cómo realizar: histogramas, diagramas de dispersión, gráficos de barras, diagrama de cajas y gráficos circulares en Matplotlib.

Mira los siguientes ejemplos en Matplotlib.
Éste artículo también está disponible en VIDEO. Míralo aquí: https://youtu.be/Ykw4jOD_bYU
Para los siguientes ejemplos utilizaremos el siguiente archivo: https://drive.google.com/file/d/1Hzljeh0TAVM3g4b_KQJTCoxKm84Ij26_/view?usp=sharing
Consiste en un CSV que contiene datos de un estudio realizado en la zona de Boston, donde se analizan diferentes variables, como son el índice de crimen, el número de habitaciones, el porcentaje de habitantes de clase baje y el valor medio de las casas de esa zona.
Pasos iniciales
Lo primero que vamos a hacer es importar las librerías necesarias, leer el archivo CSV y renombrar las columnas para una mejor comprensión.
import pandas as pd
import matplotlib.pyplot as plt
datos = pd.read_csv("casasboston.csv")
#datos = datos[["RM","CRIM", "MEDV", "TOWN", "CHAS", "INDUS", "LSTAT"]]
df = datos[["RM","CRIM", "MEDV", "TOWN", "CHAS"]]
df = datos.rename(columns={
"TOWN":"CIUDAD",
"CRIM":"INDICE_CRIMEN",
"INDUS":"PCT_ZONA_INDUSTRIAL",
"CHAS":"RIO_CHARLES",
"RM":"N_HABITACIONES_MEDIO",
"MEDV":"VALOR_MEDIANO",
"LSTAT":"PCT_CLASE_BAJA"
})
print (df.sample(5))
Puedes consultar el siguiente enlace si deseas comprender mejor cómo se trabaja con pandas en Python:
Pandas en Python: lo que debes saber para comenzar.
Ejemplos en Matplotlib en Python y Pandas
Histogramas
Un histograma es útil para ver la distribución de una variable, es decir, nos permite ver los valores más comunes.
En el siguiente ejemplo deseamos ver la distribución de la cantidad media de habitaciones en el estudio realizado.
df.N_HABITACIONES_MEDIO.plot.hist() plt.show()
Y nos devuelve:
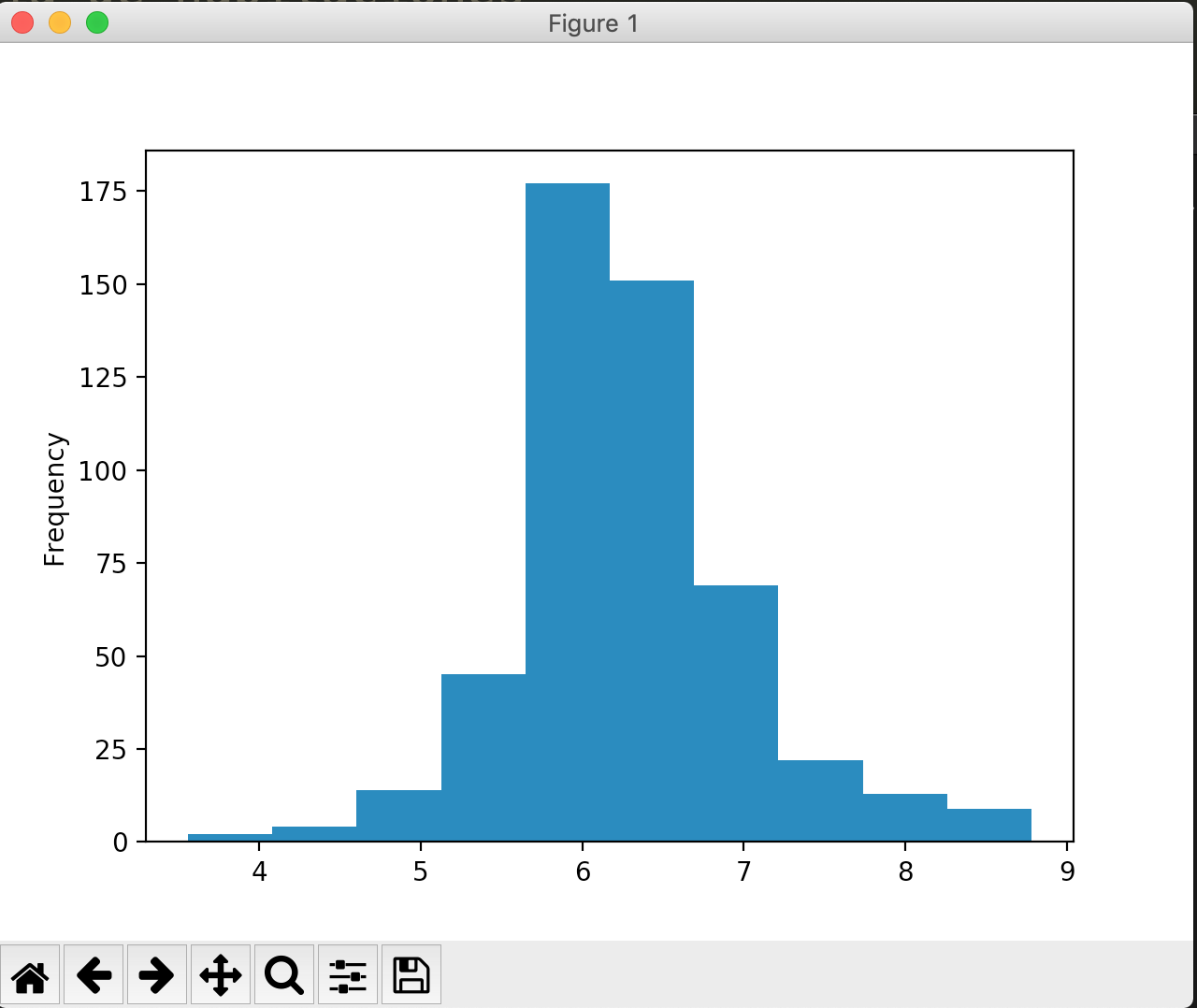
Un gráfico de éste tipo nos permite ver fácilmente que la mayor parte de las casas registradas cuentan con 6 o 7 habitaciones.
Otro ejemplo sería si deseamos ver la distribución del índice de crimen. Podemos utilizar bins para especificar la cantidad de grupos en los que deseamos distribuir los casos, y xlim para centrarnos en algunos grupos en específico.
df.INDICE_CRIMEN.plot.hist(bins=100, xlim=(0,20)) plt.show()
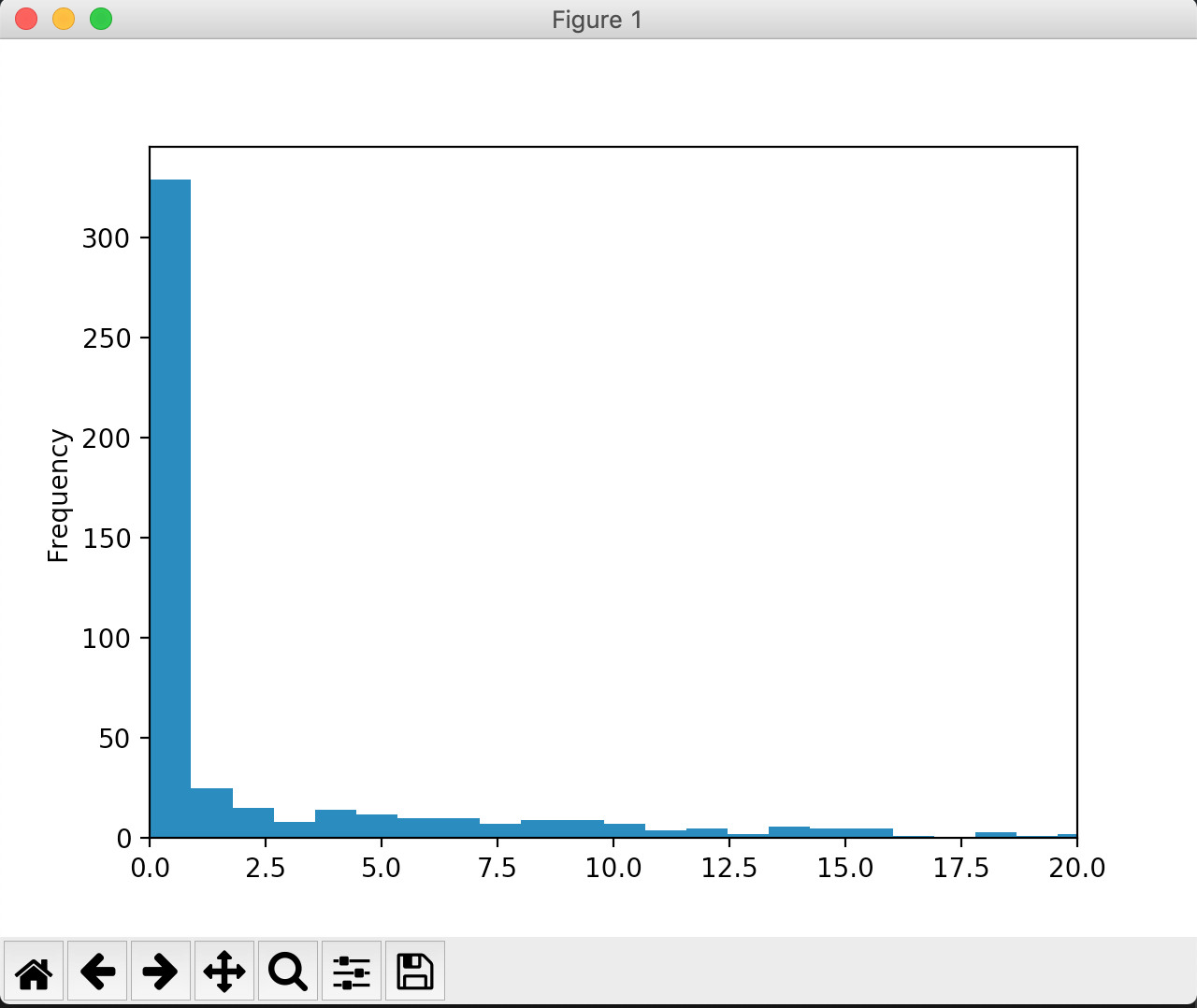
Gráfico de dispersión
El gráfico de dispersión o scatter, sirve para representar la relación entre dos variables. Por ejemplo, si quisiésemos ver la relación entre índice de crimen y el valor mediano de las casas. En otras palabras, ¿el índice de crimen afecta el valor medio de las casas?
df.plot.scatter(x="INDICE_CRIMEN", y="VALOR_MEDIANO", alpha=0.2) plt.show()
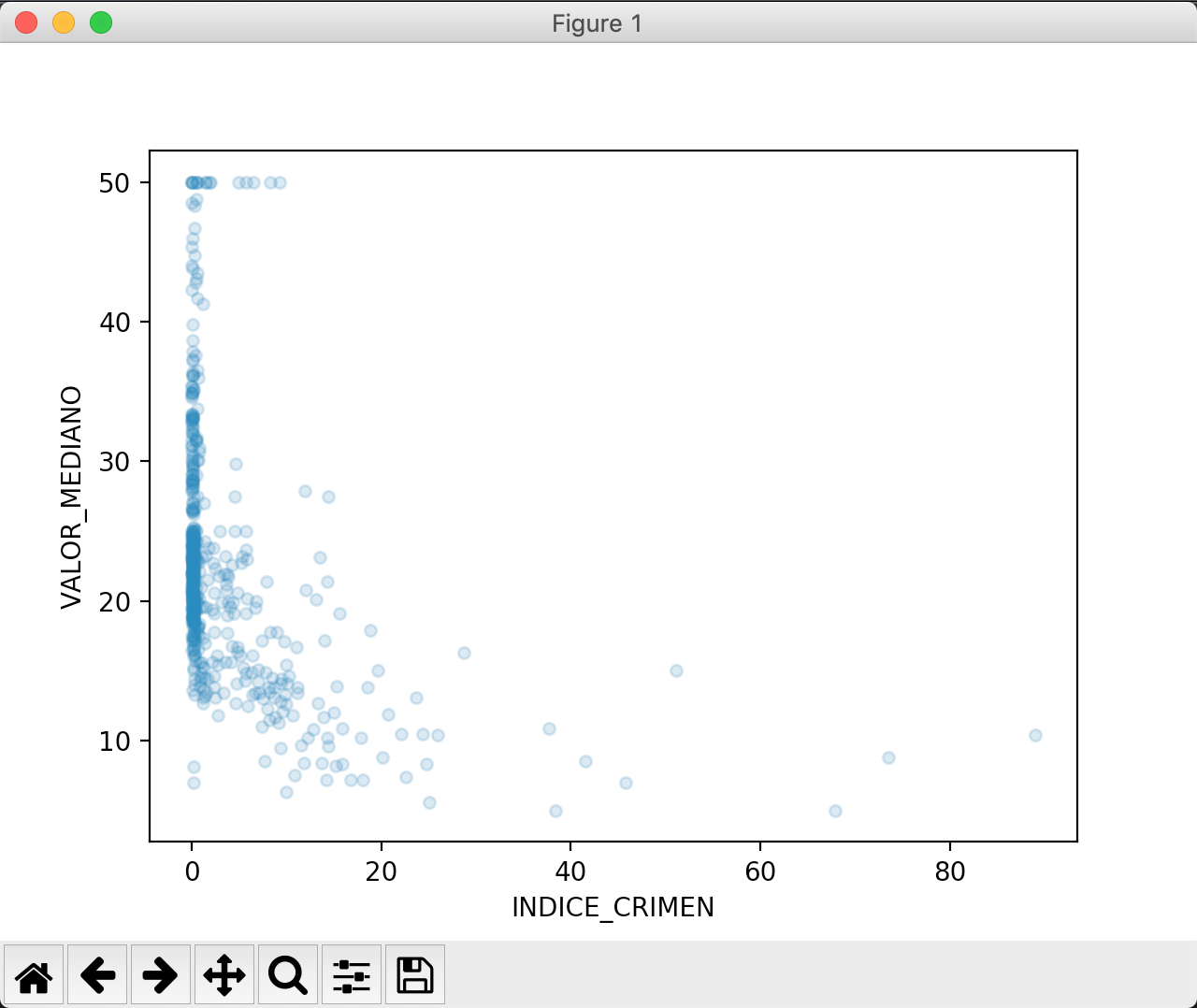
El gráfico nos deja ver que a menor índice de crimen el valor mediano aumenta, por lo que pudiésemos concluir que ambos valores están correlacionados.
Gráfico de barras
Un gráfico de barras es útil para comparar una variable entre distintos grupos o categorías. Por ejemplo, si quisiéramos observar el valor medio de cada ciudad.
Tenemos el valor medio de zonas dentro de una ciudad, así que la única forma de obtener el dato de la media de toda la ciudad, sería realizando una operación de agrupación. (Para más información sobre agrupación en Pandas consulta: Filtrado y uso de query con Pandas en Python).
El siguiente código agrupa por ciudad, y toma la media del valor_mediano. Después grafica las 10 primeras ciudades.
valor_por_ciudad = df.groupby("CIUDAD")["VALOR_MEDIANO"].mean()
valor_por_ciudad.head(10).plot.barh()
plt.show()
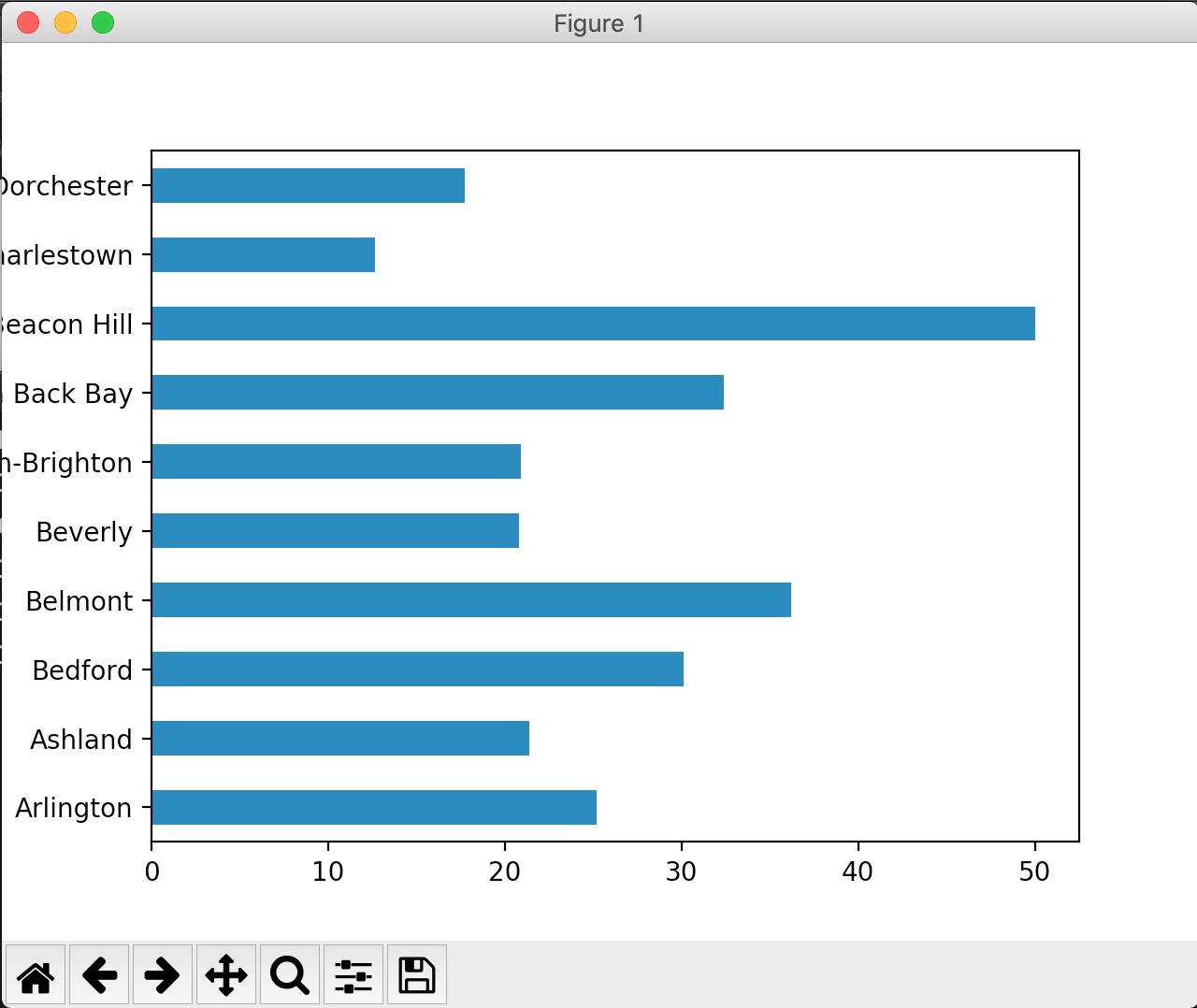
El agrupamiento realizado en Pandas y graficado con Matlplotlib, nos permite de forma rápida y sencilla observar qué ciudades tienen el valor medio más alto para sus propiedades.
Diagrama de cajas
Los diagramas de cajas son útiles para representar grupos de datos y compararlos entre ellos. Otro uso importante es que nos permiten identificar de forma sencilla si una variable tiene muchos outliers (valores atípicos) esto es, elementos que se alejan de los valores frecuentes de dicha variable.
Por ejemplo, si deseamos ver los valores atípicos de índice de crimen en los diferentes cuantiles de valor mediano.
Primero vamos a agrupar los datos de “valor_mediano” en 5 cuantiles. Con esa clasificación vamos a realizar el gráfico contemplando el índice de crimen por cada cuantil.
df["VALOR_CUANTILES"] = pd.qcut(df.VALOR_MEDIANO, 5) df.boxplot(column="INDICE_CRIMEN", by="VALOR_CUANTILES", figsize=(8,6)) plt.show()
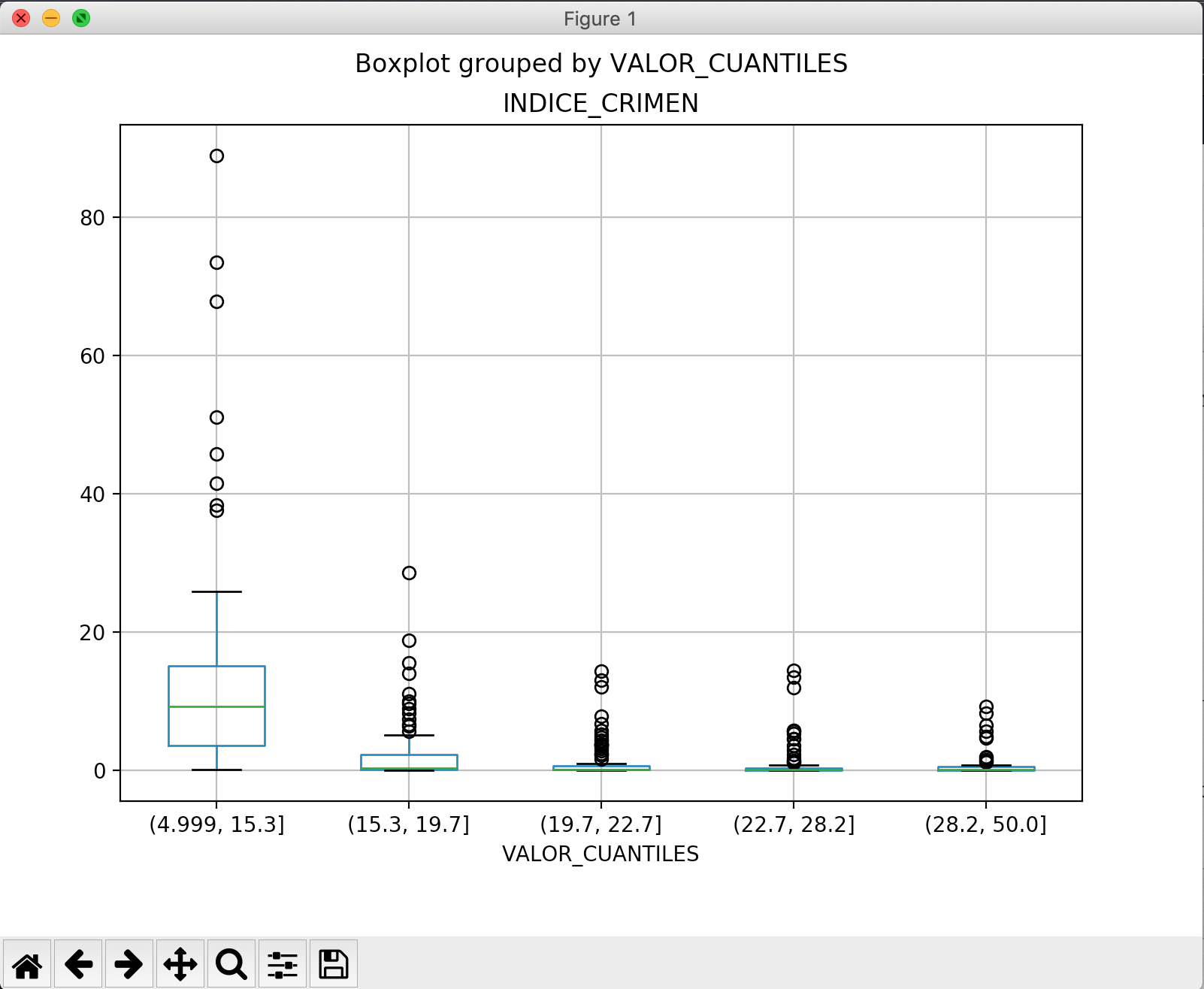
Vemos 5 grupos de datos, son los valores de las casas agrupadas por cuantiles. A la izquierda están las casas que tienen menor valor y a la derecha las que tienen más valor. En cada columna hay una caja de color azul que tiene una linea central verde. Esa línea representa la mediana. Y el cuadro azul agrupa el 50% de los datos. Las otras líneas representan los límites superior e inferior. Todos los datos que estén fuera de esos límites se consideran atípicos y están representados por pequeños círculos vacíos en el diagrama.
Éste gráfico nos permite ver fácilmente los valores atípicos de un conjunto de datos.
Gráfico circular
Un gráfico circular se usa para mostrar la relación porcentual entre las partes con relación a su conjunto. En nuestro ejemplo hay una columna que se llama “Rio_Charles”, que contiene un 1 si la propiedad está cerca del río charles y un 0 si no lo está. Con esto podemos crear un gráfico circular que nos deje ver la proporción de lugares cerca y no cerca del río charles.
df.RIO_CHARLES.value_counts().plot.pie() plt.show()
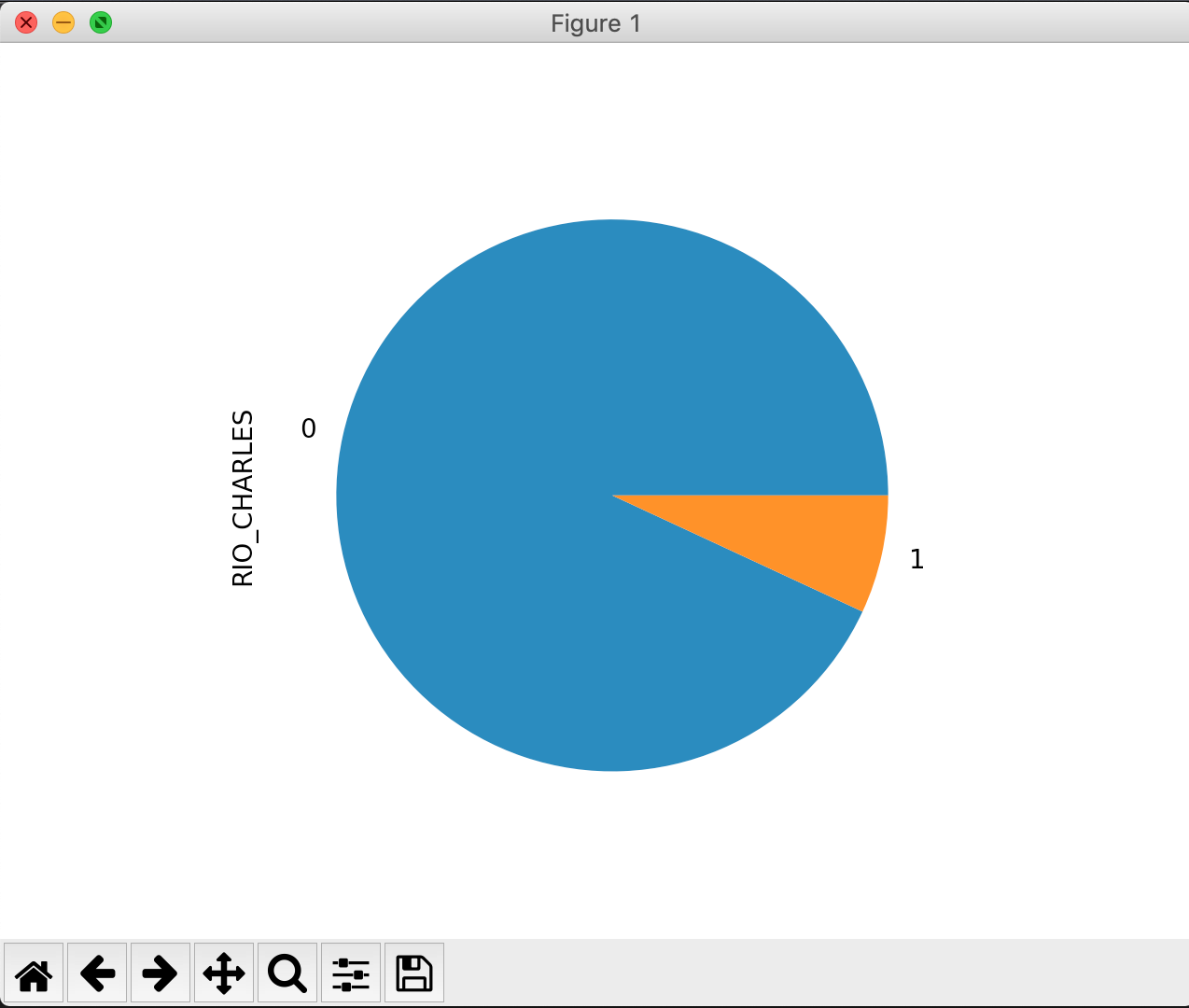
Espero que éstos ejemplos en Matplotlib te hayan ayudado a entender mejor el uso de algunos gráficos.
Todo lo anterior también lo puedes ver en el siguiente video: