Vectorizar texto para tareas de machine learning y matrices dispersas
Para realizar tareas de Machine Learning sobre elementos de texto, por ejemplo, para entrenar un clasificador, se requerirá vectorizar texto, es decir codificar las palabras como números.
Ilustraremos el proceso con el siguiente ejemplo sencillo.
En el siguiente texto tenemos tres frases:
- El perro mordió al gato
- El gato mordió al ratón
- Al ratón le gusta el queso del gato
Lo primero que haríamos sería eliminar las palabras que no aportan mucho significado al texto, por ejemplo, el, al, del, le.
Eso nos dejaría las frases asi:
- Perro mordio gato
- Gato mordio raton
- Raton gusta queso gato
En algunas ocasiones también es conveniente eliminar los acentos o tildes de las palabras.
Cómo vectorizar texto para tareas de machine learning
Ahora podemos vectorizar el texto, es decir codificar las palabras como números. Una forma sencilla es creando una matriz dispersa.
En el ejemplo que estamos viendo, tendríamos tres filas, una por cada frase.

Las columnas representarían cada palabra. En nuestro texto tenemos un total de 6 palabras:

Así para la primer frase: Perro mordio gato, representaríamos cada palabra con un número, por ejemplo: 1

El resto de las ubicaciones contendría un 0.
Para la segunda y tercer frase, en la segunda y tercer fila colocaríamos los unos correspondientes:

Así, tenemos una matriz dispersa, es decir una matriz donde la mayoría de los valores serán ceros. (Puedes consultar: Matrices dispersas (Rodríguez, 2019))
Considere que entre mayor sea la cantidad de palabras, mayor será la cantidad de columnas por lo que la cantidad de ceros superará la cantidad de unos.
Ahora bien, aunque comunmente relacionemos el cero con un valor nulo, para la computadora, el cero ocupa un espacio similar al de cualquier otro número.
Así es que una forma de optimizar el espacio e incrementar la velocidad de procesamiento de la matriz es almacenar los unos en tres vectores V, I, J
En el vector V, se almacenará el dato que contiene la matriz dispersa en la coordenada I, J.
Es decir, si en la posición 0,0 de la matriz dispersa hay un 1. En el vector I, habrá un 0, en el vector J habrá un 0 (en la misma posición) y en el vector V estará el valor, en este caso un 1.
(0,0) 1
De modo que al final, toda nuestra matriz dispersa puede quedar representada por esos tres vectores:
(I, J) V
(0,0) 1
(0,2) 1
(0,3) 1
(1,0) 1
(1,1) 1
(1,5) 1
(2,0) 1
(2,1) 1
(2,4) 1
(2,5) 1
Vectorizar texto usando Python
Veamos ahora un ejemplo en Python que nos ilustra lo que acabamos de realizar.
descripcion "perro mordio gato" "gato mordio raton" "raton gusta queso gato"
Primero, tenemos un archivo de texto con las 3 frases que usamos de ejemplo. El archivo está en formato CSV, es decir, valores separados por comas. Solo contiene una columna llamada “descripcion”
En el siguiente código haremos uso de CountVectorizer para extraer las palabras y codificarlas como un vector.
También utilizaremos TfIdVectorizer para calcular la frecuencia de las palabras. El método que esta función utiliza se llama TF-IDF (que significa algo así como: Frecuencia de Término – Frecuencia Inversa de Documento). No profundizaremos en los cálculos que éste método realiza, pero considere que TF-IDF son puntuaciones de la frecuencia de las palabras dentro de un documento.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
palabras = pd.read_csv("palabras.csv")
contador = CountVectorizer()
vectorizador = TfidfVectorizer(max_features=10)
#Crear una matriz dispersa
cantidades = contador.fit_transform(palabras.descripcion)
valores = vectorizador.fit_transform(palabras.descripcion)
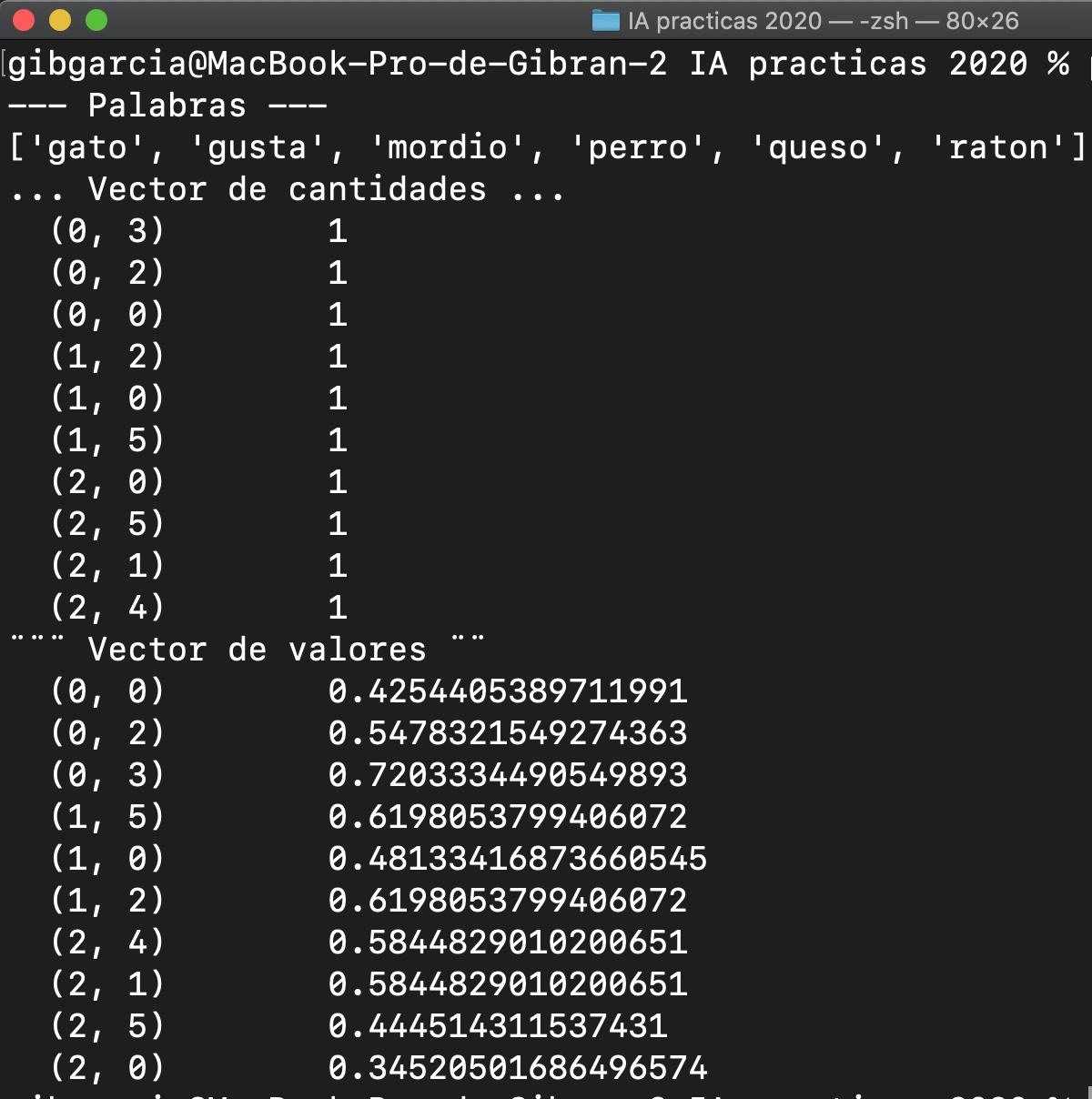
print ("--- Palabras ---")
print(vectorizador.get_feature_names())
print ("... Vector de cantidades ...")
print (cantidades)
print ("¨¨¨ Vector de valores ¨¨")
print (valores)
Como podemos observar, la clase TfIdfVectorizer nos crea los vectores de valores correspondientes a la matriz dispersa que contiene las palabras de nuestro archivo. Estos valores son los que utilizaríamos para entrenar nuestro modelo de machine learning.
Mira esto en video: