Fases del análisis de datos usando Python: Distribución de Variables
Veremos la siguiente fase del análisis de datos usando Python: Distribución de Variables. Usaremos histogramas, gráfico de probabilidad y test de normalidad.
Las primeras fases las puedes encontrar en el siguiente enlace: https://naps.com.mx/blog/fases-del-analisis-de-datos-usando-python/
Fase 4. Distribución de variables
Librerías a utilizar
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Cargar el archivo generado en el paso anterior:
vehiculos = pd.read_pickle("vehiculospaso3.pkl")
Debemos ver cómo interpreta Pandas los datos, es decir, qué tipo de dato le asigna a cada uno.
print(vehiculos.dtypes)
Lo que nos arroja:
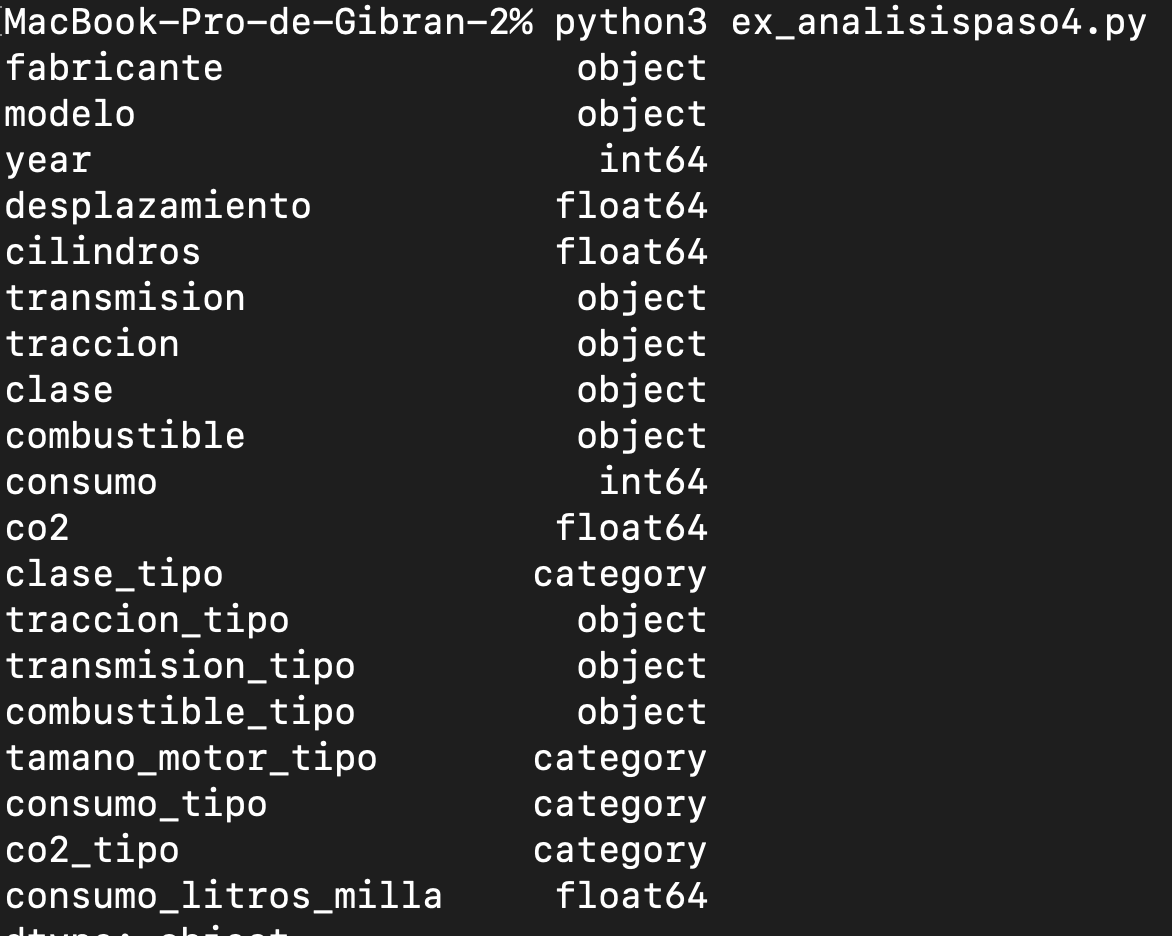
Observamos que hay variables numéricas y variables categóricas (que creamos en el paso anterior).
Lo que vamos a hacer es analizar la distribución de las variables
Distribución de variables numéricas
Histogramas
Podemos crear un histograma para ver la distribución de una variable. Por ejemplo, tenemos una columna llamada co2, donde se registra el nivel de contaminación que emite cada vehículo. ¿Cómo es la distribución de ésta variable? Creamos un histograma para esa columna.
vehiculos['co2'].plot.hist();
Recuerda añadir plt.show() si ejecutas tus programas desde línea de comandos.
El histograma se muestra de ésta forma:

Podemos hacer lo mismo con el resto de variables numéricas. Observamos que al parecer siguen una distribución normal. Recordarás la típica forma de «campana» que tiene una distribución normal. Es importante saber si nuestras variables siguen una distribución normal dado que muchos algoritmos asumen éste tipo de distribución.
Gráfico de probabilidad
Otra forma de comprobar esto es usando un gráfico de probabilidad.
Vamos a crear la siguiente función que utiliza la librería scipy:
from scipy import stats
def normalidad_variable_numerica(col):
stats.probplot(vehiculos[col], plot=plt)
plt.xlabel('Diagrama de Probabilidad(normal) de la variable {}'.format(col))
plt.show()
Vamos a probar con la misma columna de hace un momento: co2. Cuanto más se parezca nuestra gráfica a una línea de 45 grados, más normal será.
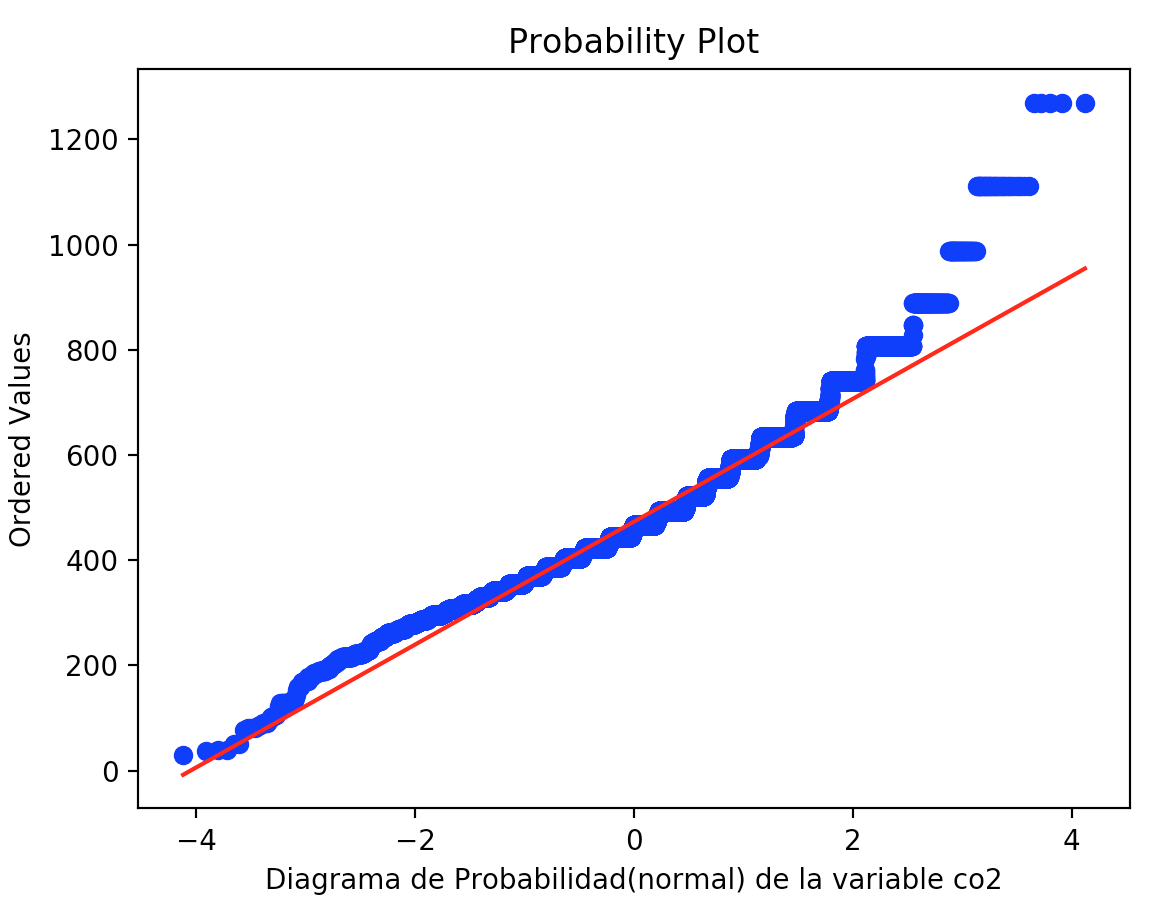
En el caso de la variable co2, se ajusta bastante a una distribución normal.
Test de normalidad
Otra forma de asegurarse de que se sigue una distribución normal es realizando un test de normalidad.
columnas_numericas = vehiculos.select_dtypes(['int', 'float']).columns
for num_col in columnas_numericas:
_, pval = stats.normaltest(vehiculos[num_col])
if(pval < 0.05):
print("Columna {} no sigue una distribución normal".format(num_col))
En un test de normalidad, aceptamos o rechazamos que una variable sigue una distribución normal, para, en el caso de un nivel de confianza de 95%, el pval sea menor o mayor a 0.05. El código anterior está diseñado para probar todas las columnas numéricas que encuentre.
Como podrás observar, estrictamente hablando, ninguna de nuestras variables sigue una distribución normal.
Distribución de variables categóricas
Te dejo una función que nos permite observar la distribución de una variable categórica. Recuerda que en el paso anterior creamos variables categóricas para simplificar el análisis de datos. Probemos con clase_tipo, una variable donde clasificamos los tipos de vehículos disponibles.
def distribucion_variable_categorica(col):
vehiculos[col].value_counts(ascending=True,normalize=True).tail(20).plot.barh()
plt.show()
distribucion_variable_categorica('clase_tipo')
El gráfico que observamos es:
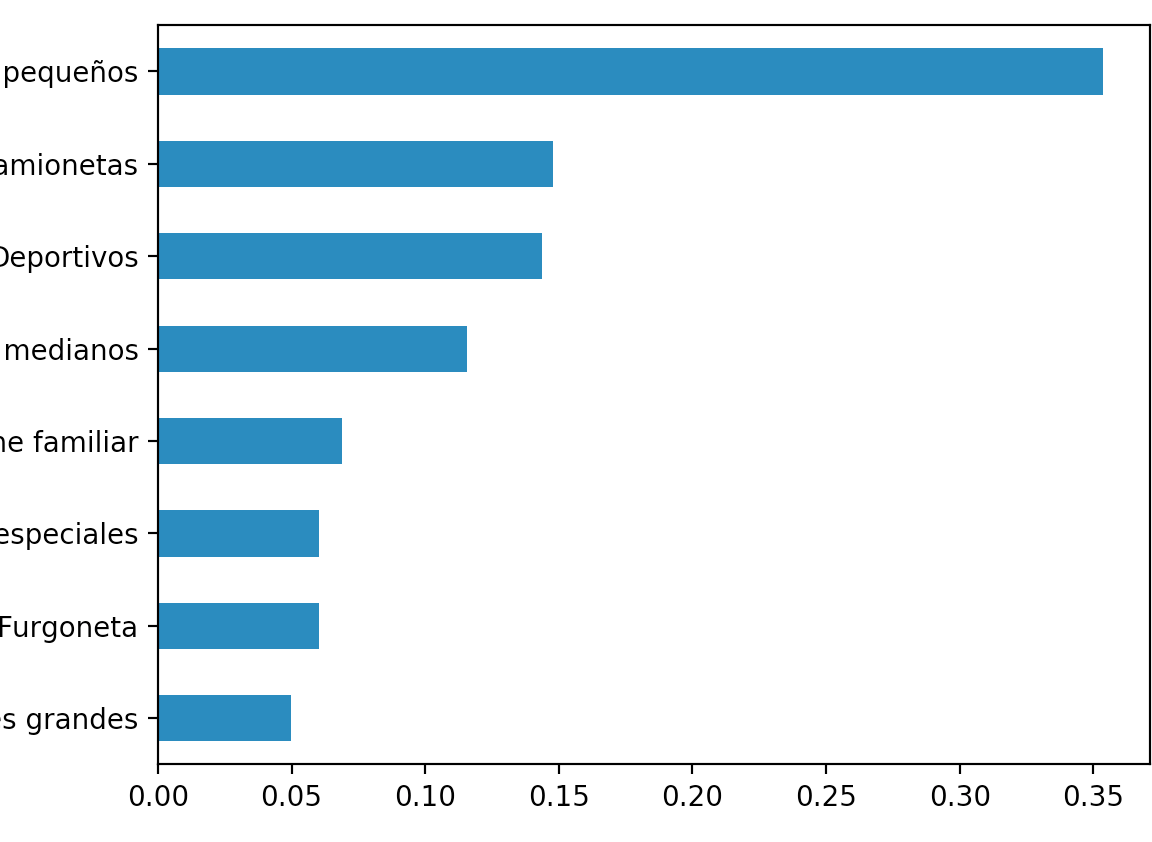
En éste caso, observamos que la clase mayoritaria de vehículos es la de coches pequeños, con un 35% del total.