3 ejemplos explicados de Machine Learning en Python
Te dejamos 3 ejemplos explicados de Machine Learning en Python usando Regresión Lineal.
Qué es Machine Learning
El Machine Learning es una rama de la Inteligencia Artificial que aplica modelos matemáticos para dotar a un computador de cierta capacidad de aprendizaje, utilizando datos históricos.
Qué es Regresión Lineal
La Regresión Lineal es un método estadístico que estudia la relación entre variables continuas y es utilizada para predecir el valor de una variable dependiente con base en el valor de otras variables independientes.
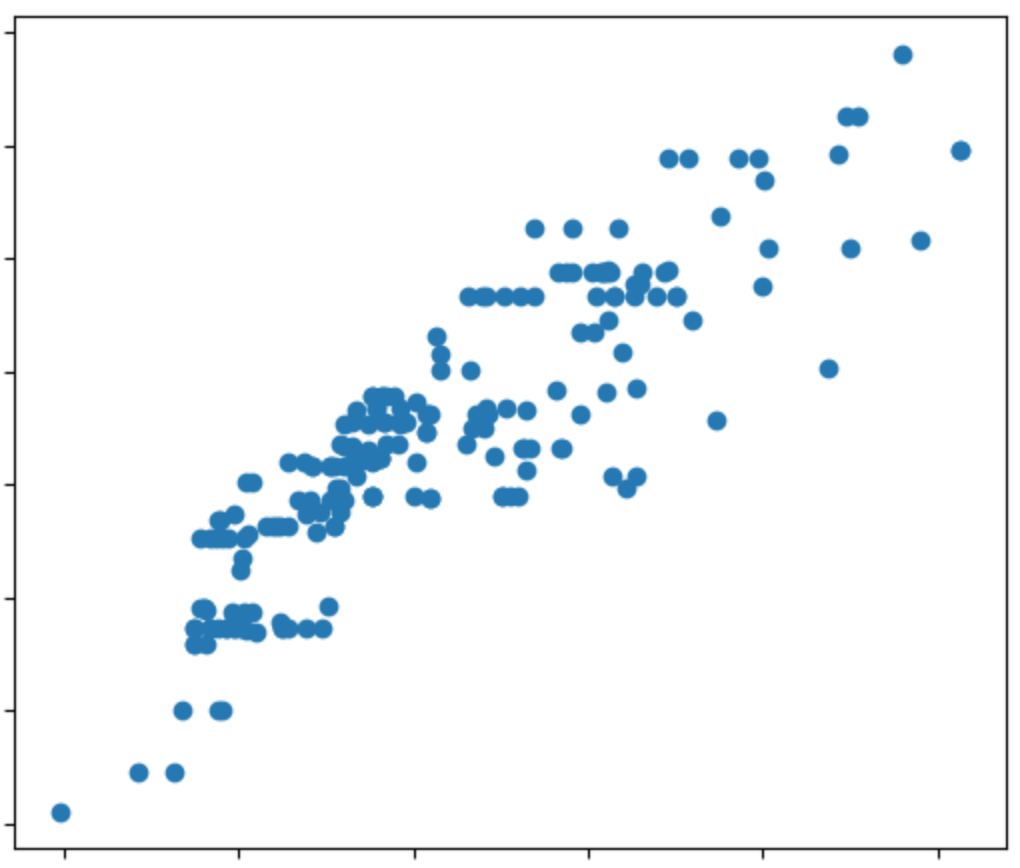
Artículo: Ejemplos explicados de Machine Learning
En la figura anterior suponga que en el eje horizontal representa el salario de una persona, y el eje vertical representa el valor de su casa. Vemos una correlación, entre más gana una persona, mayor es el valor de su casa. Claro, no siempre es así. Vemos que siempre hay personas que tienen un menor salario, pero cuentan con casas cuyo valor es superior a la casa de algunos que ganan más que él.
En el ejemplo anterior, la idea de la Regresión Lineal es darle a la computadora un valor X (salario) y que nos prediga qué valor y (costo de la casa) tendrá.
Machine Learning en Python
Python es un lenguaje de programación que nos ahorra realizar todos los cálculos y operaciones manuales que se realizan con los datos. Al utilizar Python para hacer Machine Learning aprovechamos la capacidad de la computadora para analizar muchos datos.
Python utiliza la librería Scikit-Learn. Scikit-Learn o sklearn es, entonces, una biblioteca para realizar Machine Learning en Python.
Si aun no instalas sklear, puedes hacerlo usando pip
pip install sklearn
Ejemplos explicados de Machine Learning
Ejemplo 1. Usar un dataset ya incluido
Vamos a necesitar datos, para entrenar un modelo, que nos sirva para realizar predicciones que utilizan regresión lineal. ¿Cómo obtener esos datos? Bueno, para nuestro primer ejemplo, podemos utilizar los datos que ya trae sklearn.
Librerías
from sklearn import datasets from sklearn.linear_model import LinearRegression import pandas as pd
La primera linea la necesitamos para obtener un dataset de ejemplo.
La segunda línea la utilizaremos para realizar la Regresión Lineal.
La tercera línea importa pandas, una librería de Python para el tratamiento de datos.
Cargar el dataset
dataset = datasets.load_boston()
En ésta linea cargamos un dataset de ejemplo que ya viene con sklearn. Contiene una cantidad de datos sobre propiedades (casas) en Boston.
Configurar las variables objetivo e independientes.
La variable objetivo es ese dato que queremos predecir. Y las variables independientes son esos valores que (según un análisis previo) concluimos influyen en la variable objetivo.
El dataset de ejemplo, ya trae configurados la variable objetivo y las variables independientes. Nosotros las vamos a pasar a nuestras propias variables.
objetivo = dataset['target'] independientes = dataset['data']
Creamos el modelo
Vamos a crear un modelo con los parámetros por defecto
modelo = LinearRegression()
Método fit
Ajustamos nuestro modelo pasándole los datos de entrenamiento y la variable objetivo.
modelo.fit(X=independientes, y=objetivo)
Método predict
Ya podemos realizar predicciones. Ahora solo vamos a utilizar los mismos datos de entrenamiento, y veremos qué valor hubiese predicho el sistema. Sólo mostraremos los primeros 5 valores.
predicciones = modelo.predict(independientes)
for y, y_pred in list(zip(objetivo, predicciones)) [:5]:
print("Valor Real: {:.3f} Valor Estimado: {:.5f}".format(y, y_pred))
En la primera línea, usamos el método predict, con los mismos valores independientes que ya tiene.
En la segunda linea tenemos un for, que asigna dos valores, y y y_pred. La función zip toma un valor de “objetivo” y lo relaciona con uno de “predicciones”. Dentro del for imprimimos esos dos valores. Como le indicamos [:5] solo nos muestra los primeros 5.
Resultados
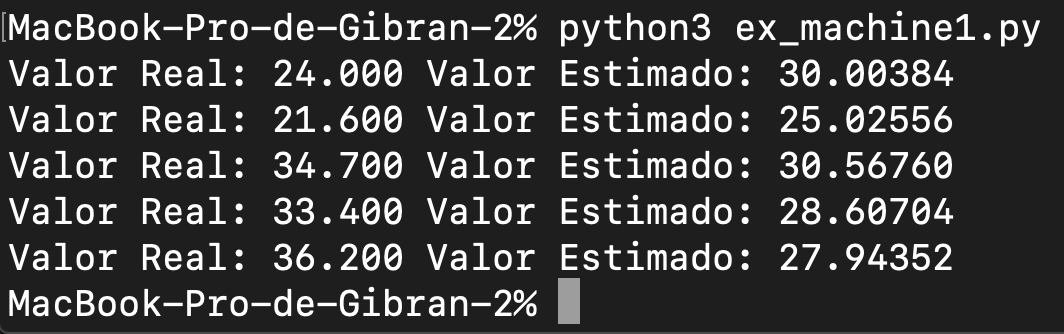
Observamos que, si le hubiésemos pasado los mismos datos que tiene ya el modelo, él hubiese predicho valores bastante cercanos a los reales.
Ejemplo 2. Usar un dataset externo
Vamos a utilizar un dataset con información sobre películas. El enlace de éste dataset está aquí:
Importamos librerías
import pandas as pd import numpy as np from sklearn.linear_model import LinearRegression
Leemos el dataset
peliculas = pd.read_csv("movies2.csv")
Si abres el archivo movies2.csv verás que contiene distintos valores. Para realizar la regresión lineal solo necesitamos los valores numéricos.
Seleccionar solo los valores numéricos
datos_numericos = peliculas.select_dtypes(np.number)
Aunque ya seleccionamos solo los valores numéricos, algunos de éstos contienen valores NaN (No es un número), por lo que vamos a reemplazarlos por 0.
datos_numericos = peliculas.select_dtypes(np.number).fillna(0)
Configurar las variables objetivo e independientes.
En nuestro caso deseamos predecir a cuánto ascenderá el monto de ventas de cierta película. Por lo que estableceremos eso como nuestra variable objetivo. Las variables independientes serán todas las demás variables numéricas que no son el objetivo.
objetivo = "ventas" #las variables independientes serian todas las demas menos ventas independientes = datos_numericos.drop(columns=objetivo).columns
Creamos el modelo y lo ajustamos
modelo = LinearRegression() modelo.fit(X=datos_numericos[independientes], y=datos_numericos[objetivo])
Agregamos las predicciones como una nueva columna del dataset original
peliculas["ventas_prediccion"] = modelo.predict(datos_numericos[independientes])
En la línea anterior, al dataset original (“peliculas”), le agregamos una nueva columna (“ventas_prediccion”) que contendrá el resultado de la predicción pasando todos los datos de las variables independientes.
Mostrar solo los campos ventas y ventas_predicción
print (peliculas[["ventas", "ventas_prediccion"]].head())
En la línea anterior imprimimos las columnas ventas y ventas_predicción, solo los primeros 5 resultados.
Resultados

La columna ventas, son las ventas reales, y la columna ventas_prediccion son los datos que el sistema hubiese predicho si le hubiéramos pasado los datos correspondientes a sus variables independientes.
Ejemplo 3. Usar nuestros propios datos
Imaginamos que hemos ido recopilando nuestros propios datos. En el siguiente ejemplo tenemos un CSV (un archivo separado por comas) con información sobre “ventas”.
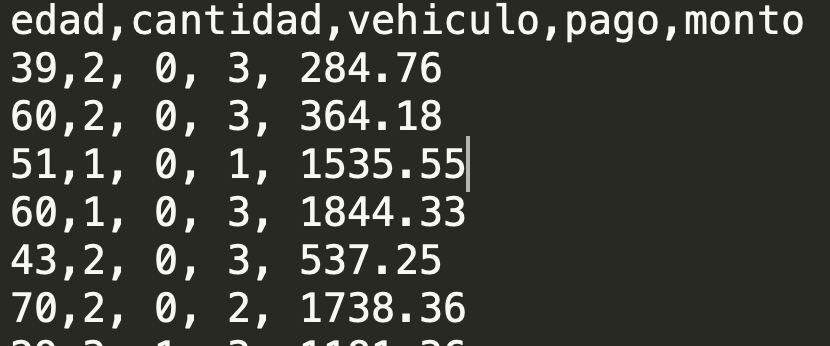
El campo edad se refiere a la edad del cliente, la columna cantidad se refiere a la cantidad de personas que iban con esa persona, la columna vehiculo indica si llegó o no en un vehículo particular, la columna pago se refiere a su forma de pago (efectivo, tarjeta de credito, débito o vales), y por último la columna monto que indica cuánto compró.
Deseamos un modelo al que le indiquemos edad, cantidad de acompañantes, vehículo y forma de pago y el nos prediga cuánto va a comprar esa persona.
Librerías a utilizar
import pandas as pd import numpy as np from sklearn.linear_model import LinearRegression
Leer el archivo y establecer las variables objetivo e independientes
ventas = pd.read_csv("ventas2.csv")
objetivo = "monto"
independientes = ventas.drop(columns=['monto']).columns
El archivo que usamos lo puedes obtener aqui. Es un archivo muy pequeño y la información no corresponde a datos reales.
Creamos el modelo y lo ajustamos
modelo = LinearRegression() modelo.fit(X=ventas[independientes], y=ventas[objetivo])
Creamos un conjunto solo con los datos ventas reales y ventas de predicción.
ventas["ventas_prediccion"] = modelo.predict(ventas[independientes]) preds = ventas[["monto", "ventas_prediccion"]].head(50)
Éste paso no es imprescindible, pero lo usaremos para graficar
Realizamos una predicción
Imagine que viene una persona de 41 años, solo, en su propio vehículo y pagando en efectivo. Entonces la lista sería: [41,1,1,1]. Vamos a pasarle ese datos al modelo y que nos prediga cuánto comprará esa persona.
talvez = modelo.predict([[41,1,1,1]])
print ("Tal vez compre: ")
print (talvez)
Observamos que una persona con esas características compraría: $1,139.31
Cabe aclarar que son datos ficticios y que no necesariamente los valores de la variable independiente están correlacionados con la variable objetivo. Solo usamos éstos datos para ejemplificar el proceso.
Graficación
Podemos ver los valores de ventas reales vs los de ventas_predicción, usando un gráfico, mostrando solo las primeras 50.
import matplotlib.pyplot as plt preds.plot(kind='bar',figsize=(18,8)) plt.grid(linewidth='2') plt.grid(linewidth='2') plt.grid(None) plt.show()
Observamos el siguiente resultado
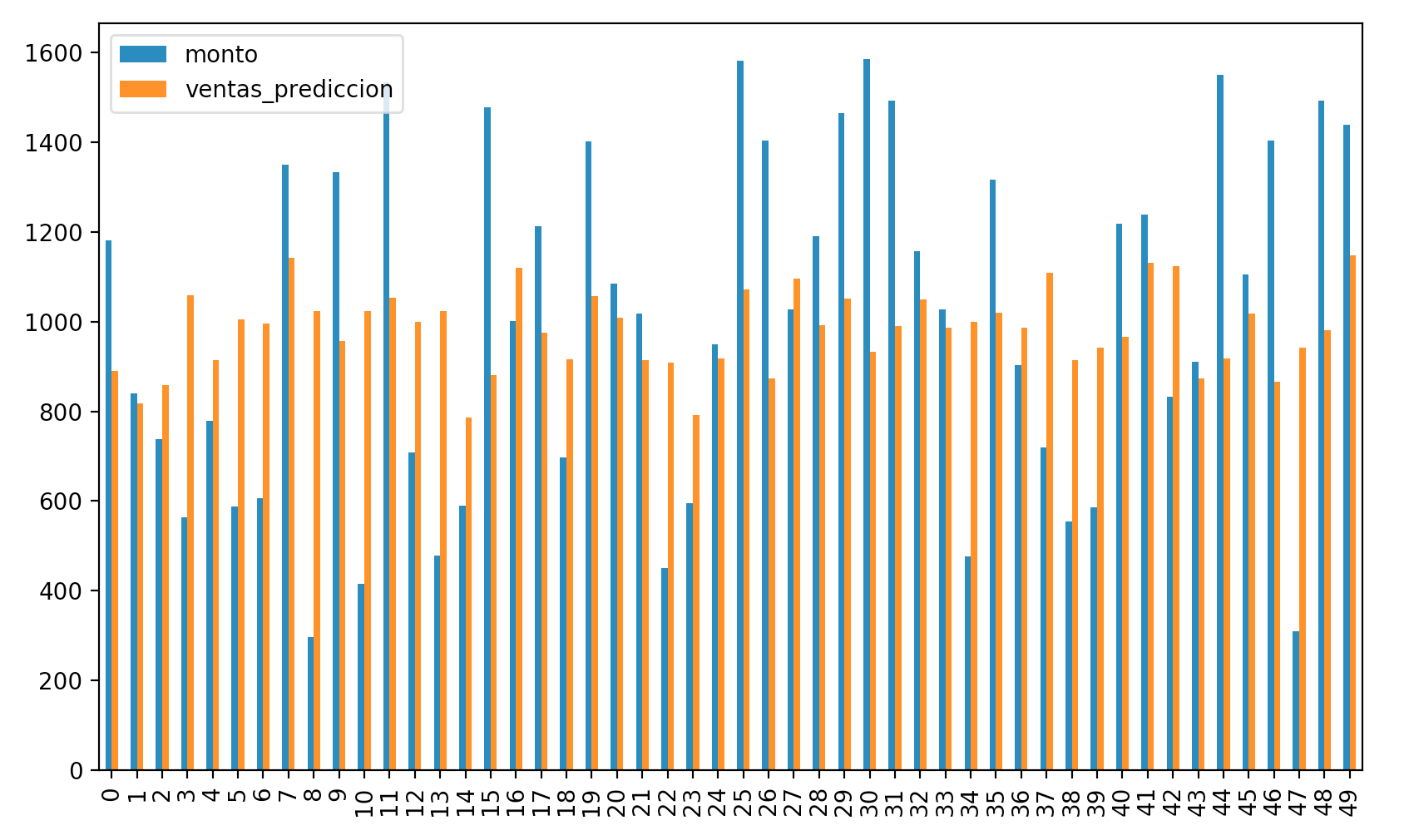
Éste modelo aún puede mejorar. Sin embargo, esperamos que te hayan servido éstos ejemplos explicados de Machine Learning usando Regresión Lineal.
¿Aprendes mejor viéndolo en video? Checa éste.